



Forum Poreklo is the official discussion board of the Society of Serbian Genealogists “Poreklo”. It was launched on January 7, 2013 (the date of Serbian Orthodox Christmas) and today is one of the largest and most visited genealogy forums in Europe. The Forum Poreklo is also the main discussion center on topics relating to the field of genetic genealogy in Southeast Europe.
The basic idea of the Forum Poreklo is to gather in one place all those who are searching for their family roots or researching the origin of their surname. By sharing the knowledge that each of us has, we gain new knowledge that helps us discover new sources and data that may be the key to discovering our origins.

At the time when the forum was launched, in addition to classical genealogical research, research in the field of genetic genealogy began to attract more and more attention. Thanks to the fact that the importance of genetic genealogy was recognized even then, the Forum Poreklo became the main place for discussions about genetic genealogy in the Serbian language in years that followed.
Due to the wide range of topics it deals with, the Forum Poreklo is divided into a number of sub-forums, and the most important sub-forums, where the largest number of discussions are held, are the Origin of Population and DNA origins.
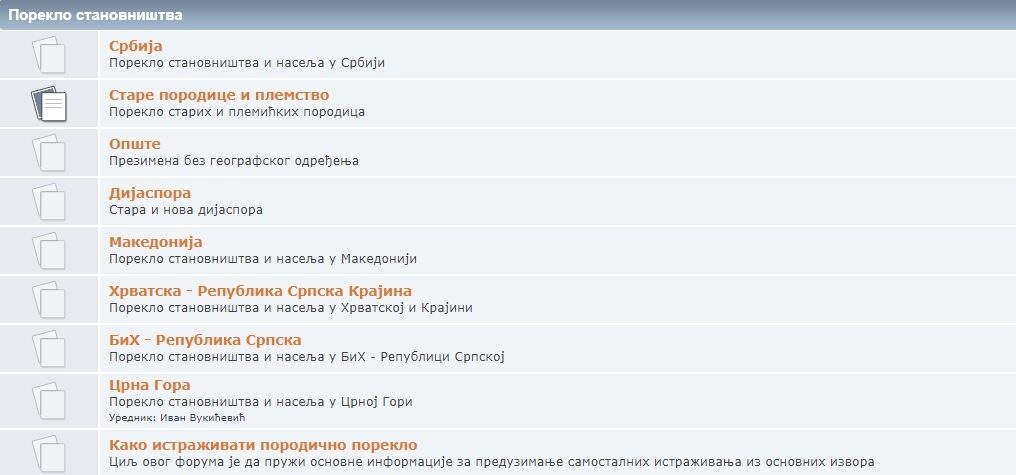
The Origin of Population sub-forum is categorized by the countries of origin (Serbia, Macedonia, Croatia / Republic of Srpska Krajina, Bosnia and Herzegovina / Republic of Srpska, Montenegro, Diaspora), while the DNA Origin sub-forum is divided in two sections – one is dedicated to Serbian DNA project activities and the other is a general section dedicated to topics from genetic genealogy.
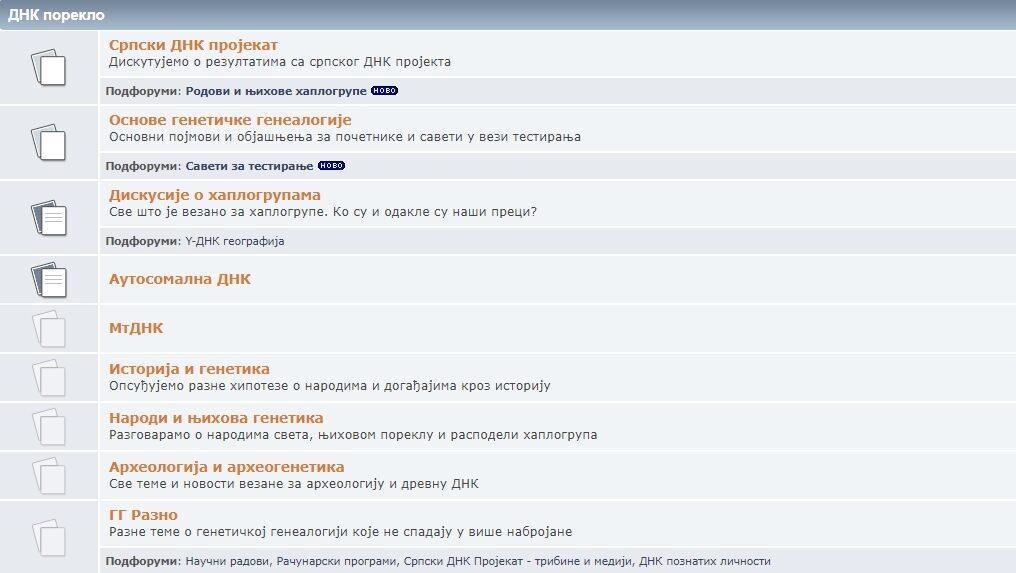
In the Forum Poreklo, in addition to the above, there are also these sub-forums: General Discussion, Sciences and Scientific Disciplines, Religion and Culture of Serbs, Warriors and Victims of War, Clues / Useful Books, Leisure and Family Search.
A special part of the forum is the sub-forum House of Serbian Genealogists “Poreklo” and Foundation “Poreklo”, dedicated to activities in search of location for the construction of the House of Serbian Genealogists and the establishment of the Foundation “Poreklo”.
It is important to point out that there is also a sub-forum of Discussions in foreign languages at the Forum Poreklo. There are the sections in English and Russian, where members who don’t speak Serbian can participate.

Most of the Members of Forum Poreklo write and understand English.
At our forum, we regularly publish the latest knowledge in the field of genealogy as well as in various genetic fields (from individual results to the results of scientific research in Serbia, its neighbors and in the world). Among the most attractive topics are certainly the Research on Family Origins, New tested on the Serbian DNA Project, Y-DNA Haplogroup I2.
The discussion is open with clear rules, which encourage a civil dialogue, while respecting all of the different opinions. We are especially proud of the fact that the largest number of participants in our forum use the Cyrillic alphabet.
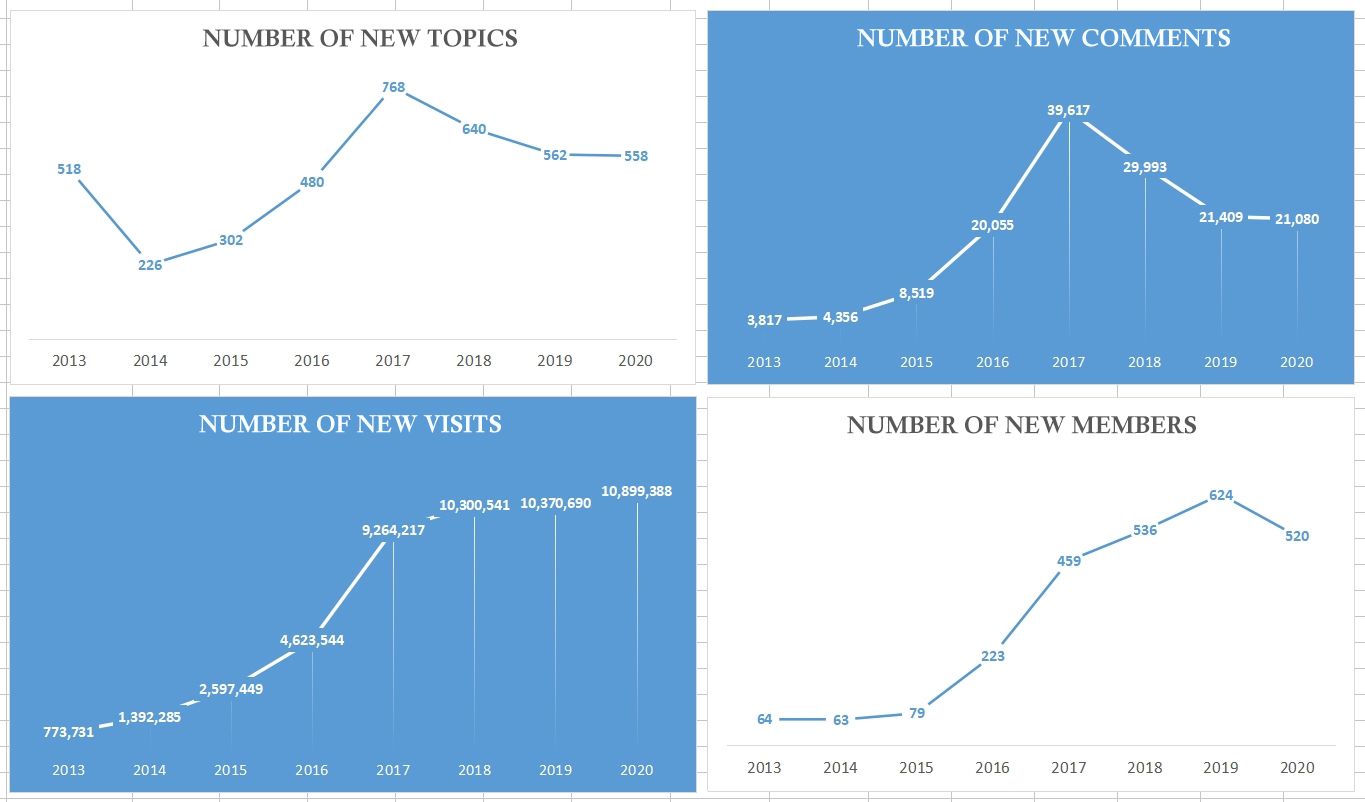
Since its founding, more than 2,500 members have joined the Forum Poreklo, more than 3,700 topics have been opened, and close to 150,000 comments have been published. In eight years, Forum Poreklo has had more than 50 million visits from Serbia and around the world.
In addition to its public work, Forum Poreklo also has a Premium Members section where information of importance for the work of the Society is published, as well as the results of some of our ongoing research, which our Society has been working on continuously in cooperation with the scientific community. Only Members of the Society of Serbian Genealogists Poreklo have access to this section.
























Коментари (0)